はじめに
使用した環境について
・Windows 10 / 64bit 環境 (21H2)
・Python 3.9.4 (tags/v3.9.4:1f2e308, Apr 6 2021, 13:40:21) [MSC v.1928 64 bit (AMD64)] on win32
icrawler ライブラリ導入
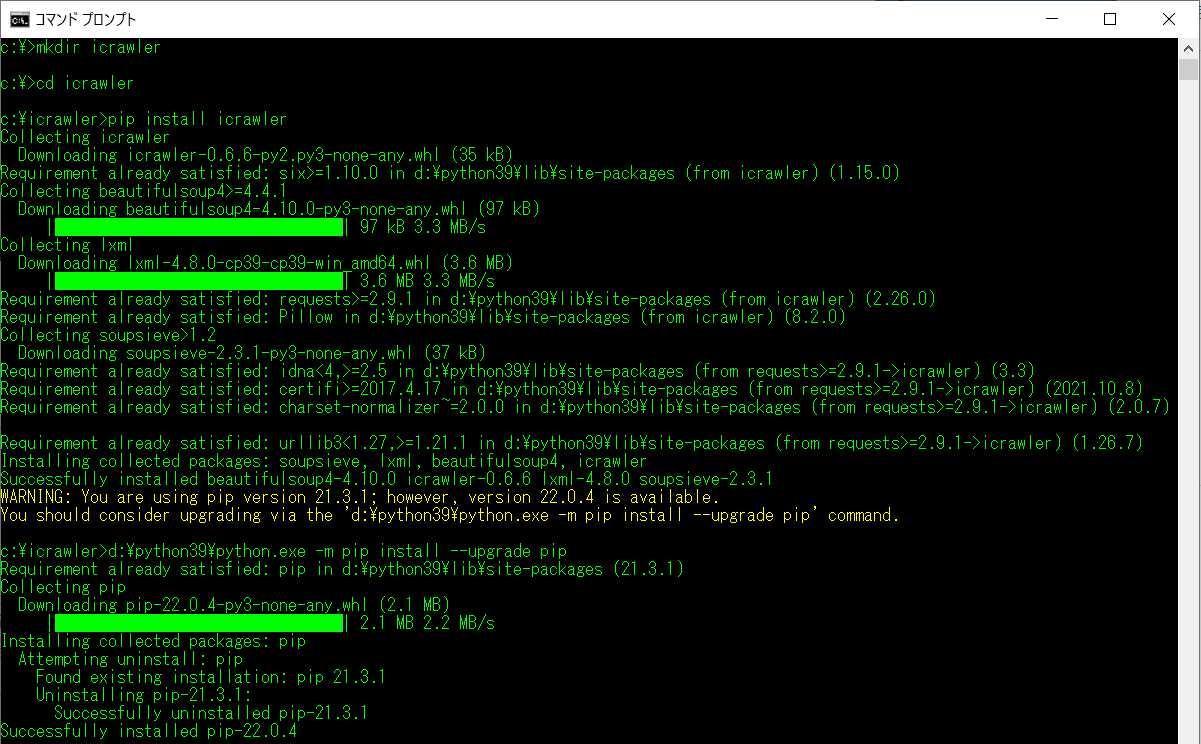
pip install icrawler を pip version が少し古い環境で実施。
ここでは先に icrawler ライブラリを導入してから upgrade pip 実行。
コマンド実行のための python script
ここでは hoge.py として C:\icrwaler に保存。
from icrawler.builtin import GoogleImageCrawler
import sys
import os
argv = sys.argv
if not os.path.isdir(argv[1]): os.makedirs(argv[1])
crawler = GoogleImageCrawler(storage = {"root_dir" : argv[1]})
crawler.crawl(keyword = argv[2], max_num = 1000)python script を実行
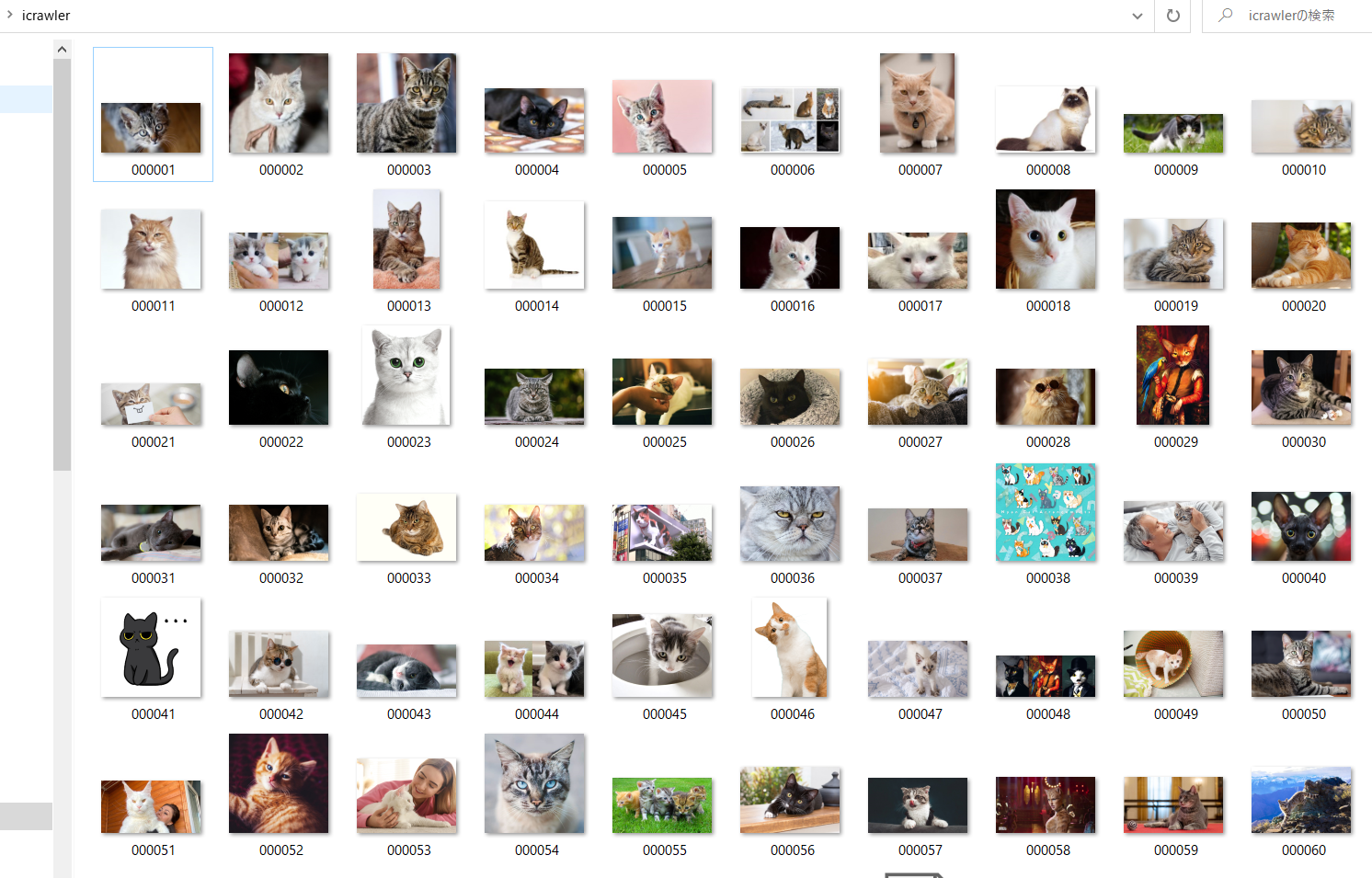
c:\icrawler カレントパスにて python hoge.py ./ cat を実行。

実行結果を Windows Explorer で参照
ML アノテーション画像集に最適ですね。
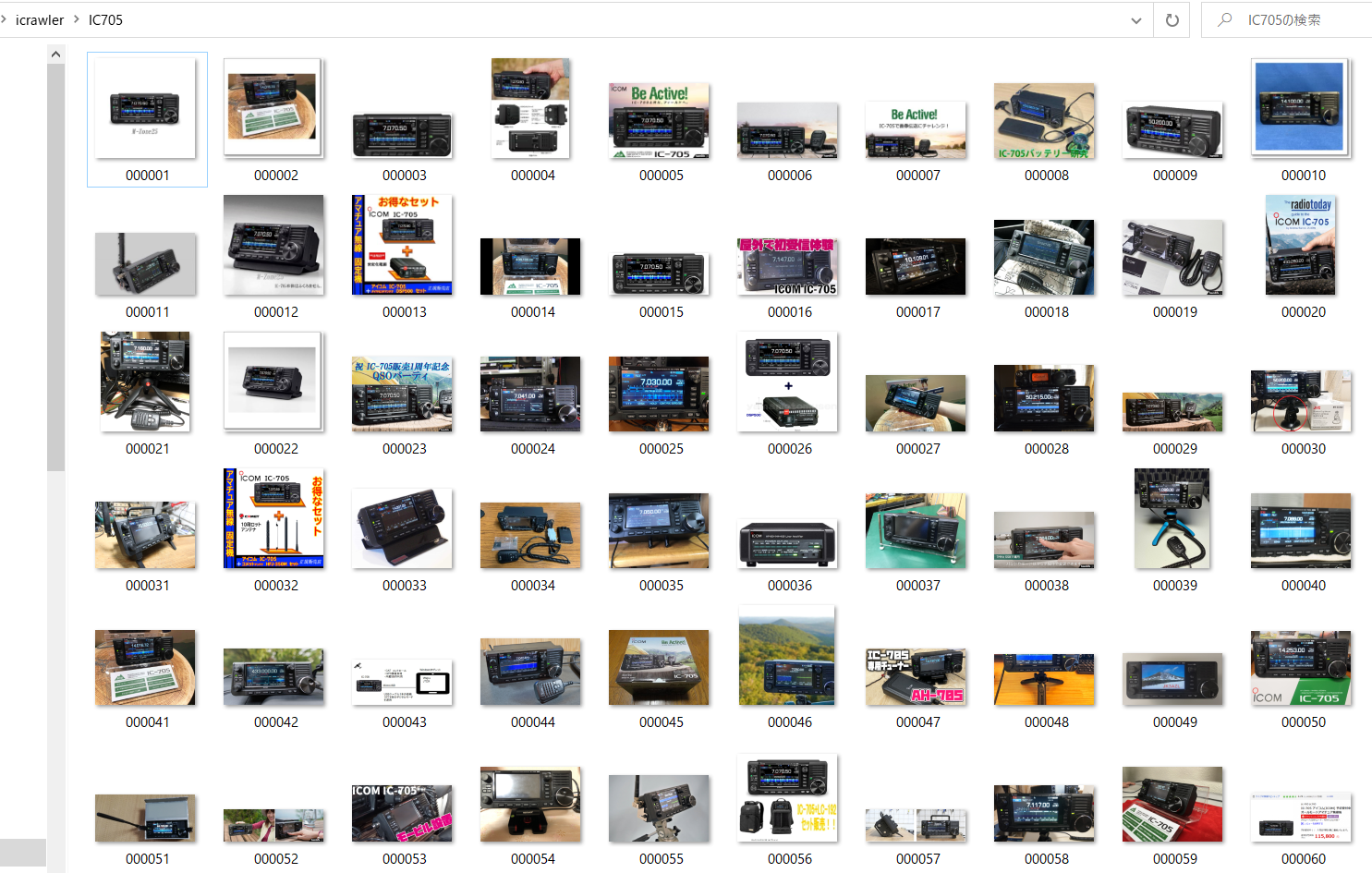
IC705 (ICOM アマチュア無線機器)画像を集めてみました。
サブフォルダ IC705 をカレントパスに作成してから、
python hoge.py /IC705 IC705 を実行。
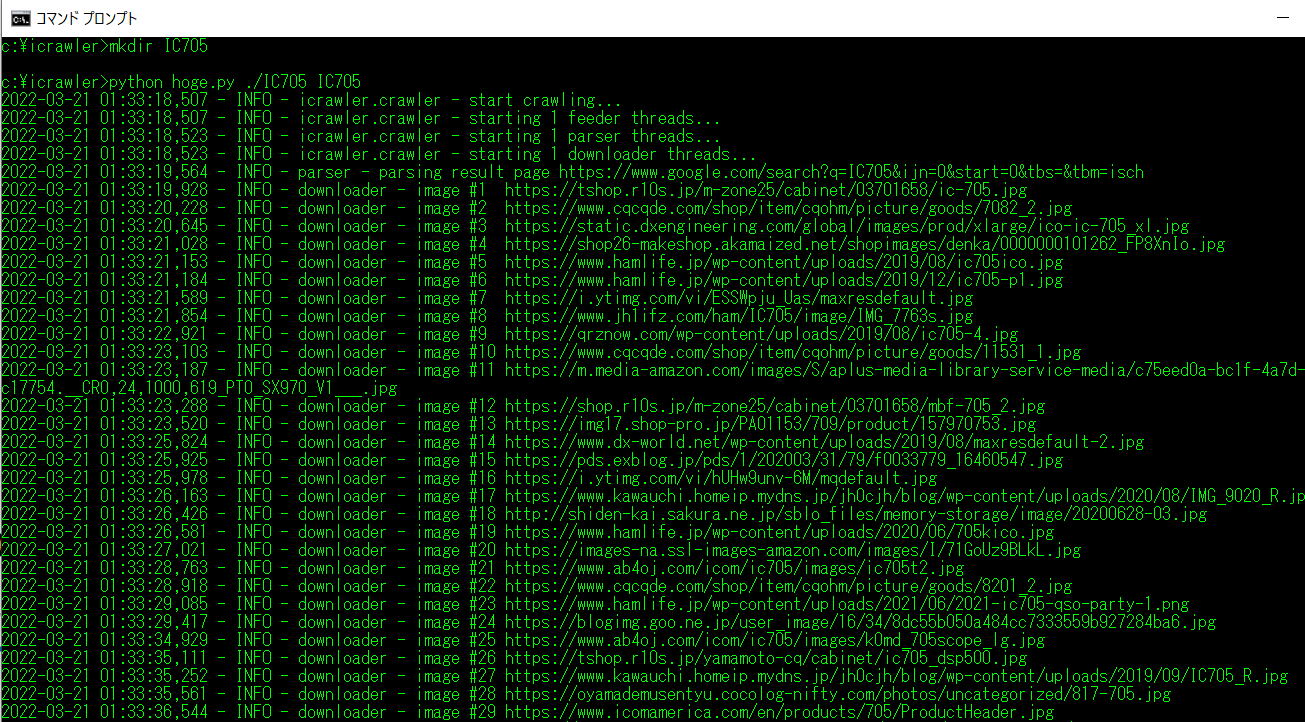
画像収集結果
これまた、一体何が嬉しいのか分からない画像収集結果となりました。
折角なので icrawler 仕様を参照します。
Docs はこちら:Welcome to icrawler — icrawler 0.6.6 documentation
Tips: Search engines will limit the number of returned images, even when we use a browser to view the result page. The limitation is usually 1000 for many search engines such as google and bing. To crawl more than 1000 images with a single keyword, we can specify different date ranges.
(snip)
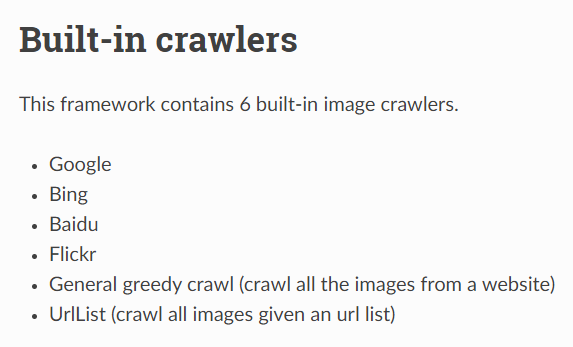
This framework contains 6 built-in image crawlers.
- Bing
- Baidu
- Flickr
- General greedy crawl (crawl all the images from a website)
- UrlList (crawl all images given an url list)
ということで、ダウンロードパスを as is のままのサンプルソールを sample.py としてカレントパスに保存。最大 1,000 件をクロールしてダウンロードするぞな。
from icrawler.builtin import BaiduImageCrawler, BingImageCrawler, GoogleImageCrawler
google_crawler = GoogleImageCrawler( feeder_threads=1, parser_threads=1, downloader_threads=4, storage={'root_dir': 'your_image_dir'})
filters = dict( size='large', color='orange', license='commercial,modify', date=((2017, 1, 1), (2017, 11, 30)))
google_crawler.crawl(keyword='cat', filters=filters, offset=0, max_num=1000, min_size=(200,200), max_size=None, file_idx_offset=0)
bing_crawler = BingImageCrawler(downloader_threads=4, storage={'root_dir': 'your_image_dir'})
bing_crawler.crawl(keyword='cat', filters=None, offset=0, max_num=1000)
baidu_crawler = BaiduImageCrawler(storage={'root_dir': 'your_image_dir'})
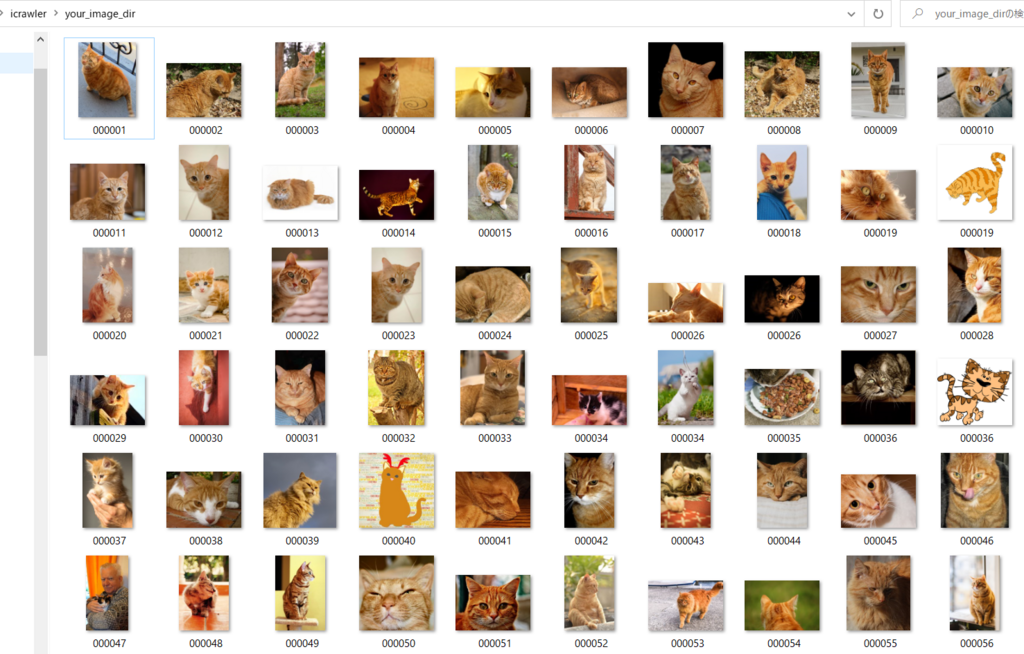
baidu_crawler.crawl(keyword='cat', offset=0, max_num=1000, min_size=(200,200), max_size=None)sample.py を実行 (引数は検索対象のみ:茶トラ)
やばい、超楽しい。
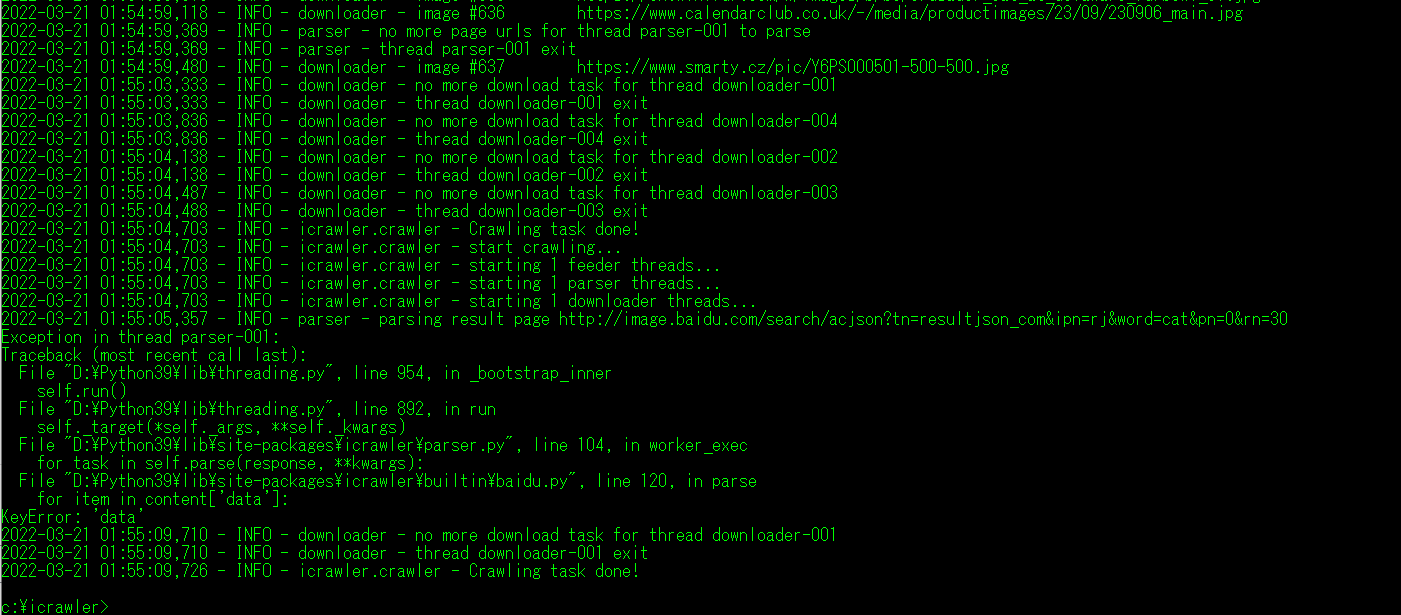
ただし、パーサーのスレッドで例外が発生してダウンロード完了せず
まとめ
お手軽な画像検索クローラによって ML アノテーション素材を集めるのがラクですね。
画像条件も指定できます:
- original
- large 2048: 2048 on longest side†
- large 1600: 1600 on longest side†
- large: 1024 on longest side*
- medium 800: 800 on longest side†
- medium 640: 640 on longest side
- medium: 500 on longest side
- small 320: 320 on longest side
- small: 240 on longest side
- thumbnail: 100 on longest side
- large square: 150×150
- square: 75×75
当然ながら収集した画像は個人用途で。
何らかの仕事用に使うのは倫理面での問題のみならず。
以上、ご覧いただき有難うございました。