はじめに
私は 2012年頃、大手電気通信事業者 法人コンタクトセンター(コールセンター)でインバウンド営業担当をしていたことがあります。受電による相談からメール/郵便を経由して受注まで行い、受注後はデリバリー担当へ引き継ぐフロント対応でした。また、その時期は AIIT で科目等履修生だったこともあり、自動音声認識 Automatic Speech Recognition (ASR) をソフトウェアだけで実現できないか、個人検討することもありましたが残念ながら別の興味を持ち自然とフェードアウト。その後、Twilio や Azure Cognitive 等でローコードによる SST/TTS などの実装を伴う技術営業は依頼があれば対応する程度。
技術営業のスキルを高めたくて普段から IBM BPLearn や NVIDIA 開発者サイトから刺激を受けています。2023/05/30 付け公開された NVIDIA 開発者サイトの記事「NVIDIA カスタマイズ音声 AI による通信業界のカスタマー エクスペリエンスの向上」は会話型AIシステムの精度に言及しており、サービス品質と顧客体験の向上を考える要素は今後の技術展望を持てる内容でした。
一般的な STT アプローチ
これまで STT アプローチは数多くありました。
Speech-To-Text(音声認識)技術は、人が話す言葉をコンピュータが理解できるテキスト情報に変換する技術で音声を使ってテキスト作成やコンピュータと対話ができます。
一般的に理解されている仕組みとして音声認識システムは、マイクや録音装置を使って音声を収集します。次に収集された音声はディジタル信号に変換されます。これにより、コンピュータが音声データを処理できる形式になります。
音声データがディジタル化されると音声認識アルゴリズムが利用され音声の特徴やパターンを分析し、その音声が含む言葉やフレーズを音の高さや長さ、周波数、強度などから分類し特定し変換します。
この変換の過程で音声認識システムは、業界固有の辞書や文法のルール、言語モデルなどの言語データベースを利用することで音声を文脈に合わせたテキストに変換できます。(個別にカスタムモデルとしてアルゴリズムへ対して強化学習することもあります)
最終的に音声認識システムはテキストを出力しコンピュータ上で再利用されるか、テキスト文書として保存します。このように Speech-To-Text 技術は音声をコンピュータが理解できるテキストに変換するための技術です。
STT エンジン NVIDIA Riva による自動音声認識パイプライン
これは前述の記事から学びました。
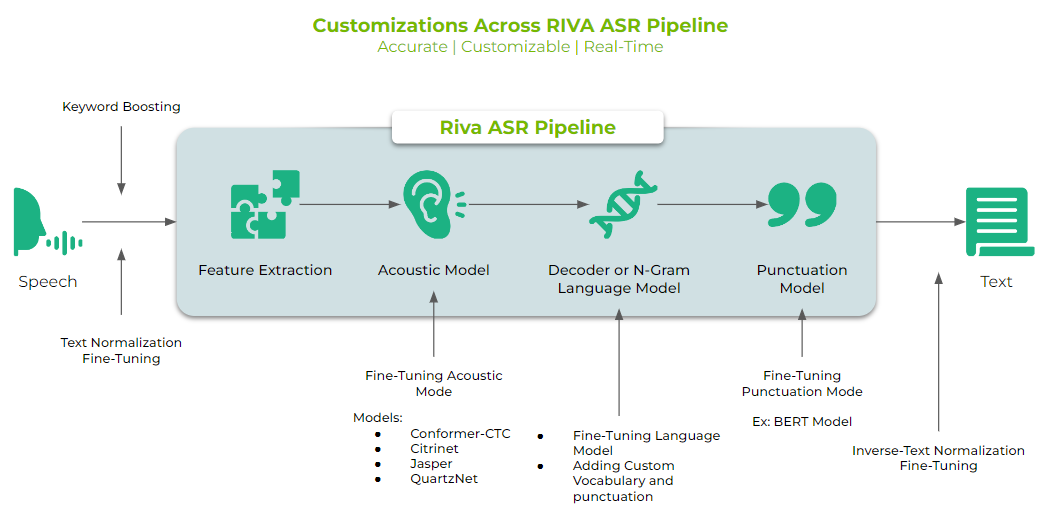
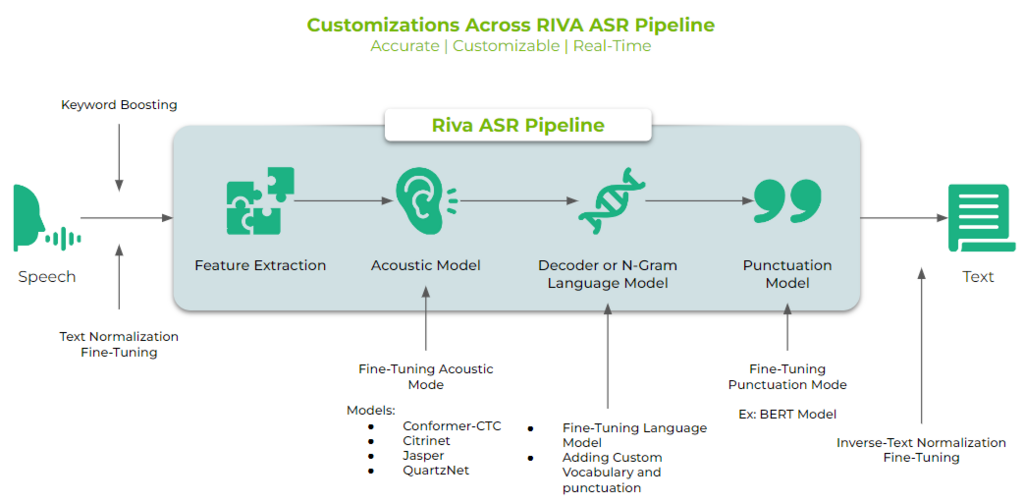
下図は ASR パイプライン全体のカスタマイズ図 です。興味深いのは Acoustic Model (音響モデル) に Fine-Tuning Acoustic Model (微調整 音響モデル)を与えられること、そして デコーダーまたは N-Gram Language Model も微調整言語モデル等を与えることができ、Punctuation Model (句読点モデル) も BERT Model などの微調整句読点モデルも与えられるので精度が向上する適応手法の仕組みを持っている点で興味深い作りとなっています。
NVIDIA RIVA: Speech AI SDK – Riva | NVIDIA
※Riva Speech AI Skills はLinux x86_64 と Linux ARM64 の 2 つのアーキテクチャをサポートしています。
補足1:
すべての適応手法の中で、ワードブースティングは実装が最も簡単で迅速です。ワード ブーストを使用すると、音響モデルの出力をデコードするときにスコアを高くすることで、要求時に関心のある特定の単語を認識するように ASR エンジンにバイアスをかけることができ、重要な単語のリストと重みをAPI呼び出しに追加のコンテキストとして渡すだけで実現可能になります。
補足2:
BERT (トランスフォーマーの双方向エンコーダ表現) は、昨年リリースされたときに自然言語理解の最先端を設定した大規模で計算集約的なモデル。微調整により、読解、感情分析、質疑応答など幅広い言語タスクに適用できます。
3億語の英語テキストの膨大なコーパスで訓練された BERT は、言語を理解するために非常に優れたパフォーマンスを発揮し、強みはラベル付けされていないデータセットでトレーニングし、最小限の変更で幅広いアプリケーションに一般化できることです。
同じ BERT を使用して複数の言語を理解し、翻訳、オートコンプリート、検索結果のランク付けなどの特定のタスクを実行するように微調整できます。この汎用性により、複雑な自然言語理解を開発するための一般的な選択肢となっています。
たとえば、「窓の外にクレーンがあります」というステートメントは、文が「湖畔のキャビンの」または「私のオフィスの」で終わるかどうかに応じて、鳥または建設現場のいずれかを表すことができます。双方向エンコードまたは非方向エンコードと呼ばれる方法を使用すると、BERT などの言語モデルではコンテキスト キューを使用してそれぞれの場合にどの意味が適用されるかをよりよく理解できます。
環境準備
NVIDIA Riva チュートリアル:
nvidia-riva/tutorials: NVIDIA Riva の実行可能なチュートリアル (github.com)
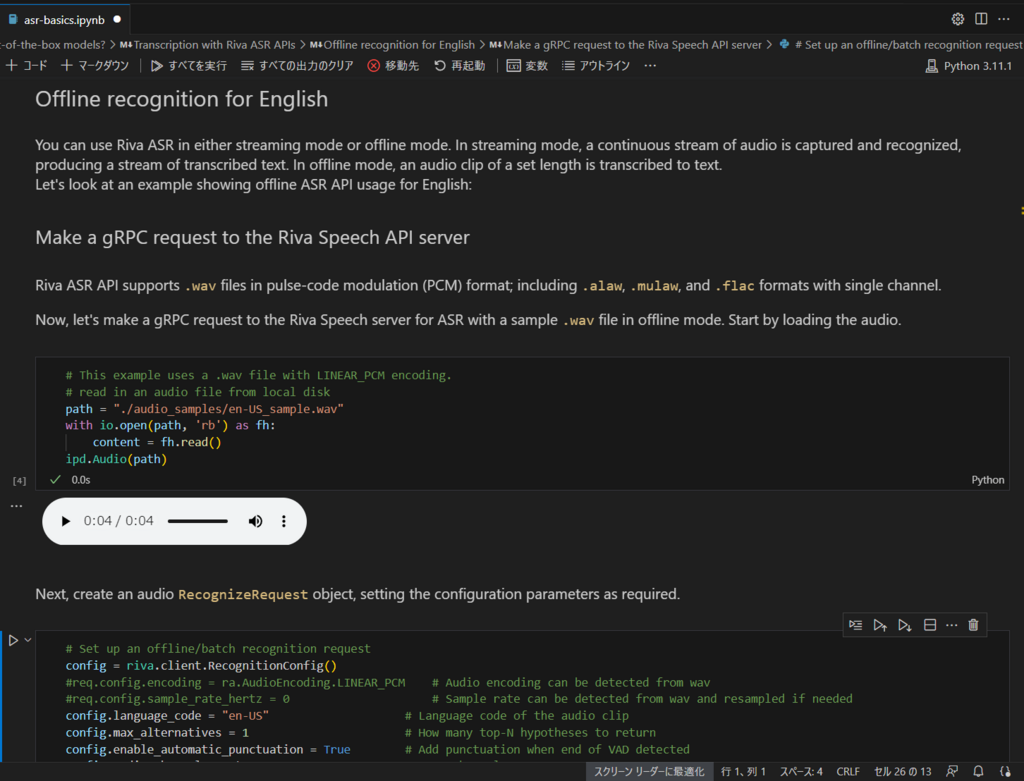
例:すぐに使用できるモデルで Riva ASR API を使用する方法
https://github.com/nvidia-riva/tutorials/blob/main/asr-basics.ipynb
物理構成:
Quick Start Guide — NVIDIA Riva
資料
関連資料:
すぐに使用できるモデルで Riva ASR API を使用するにはどうすればよいですか?— NVIDIA Riva
語彙マッピングを使用して Riva ASR の語彙と発音をカスタマイズする方法 — NVIDIA Riva
特定の単語の認識を向上させる方法 — NVIDIA Riva
TAO ツールキットを使用して Riva ASR 音響モデル (Conformer-CTC) を微調整する方法 — NVIDIA Riva
関連アプリケーションベンダー:
Google Cloud のコンタクトセンター AI プラットフォーム: すべてのチャネルでシームレスなカスタマー エクスペリエンスを大規模に提供 – Quantiphi, Inc.
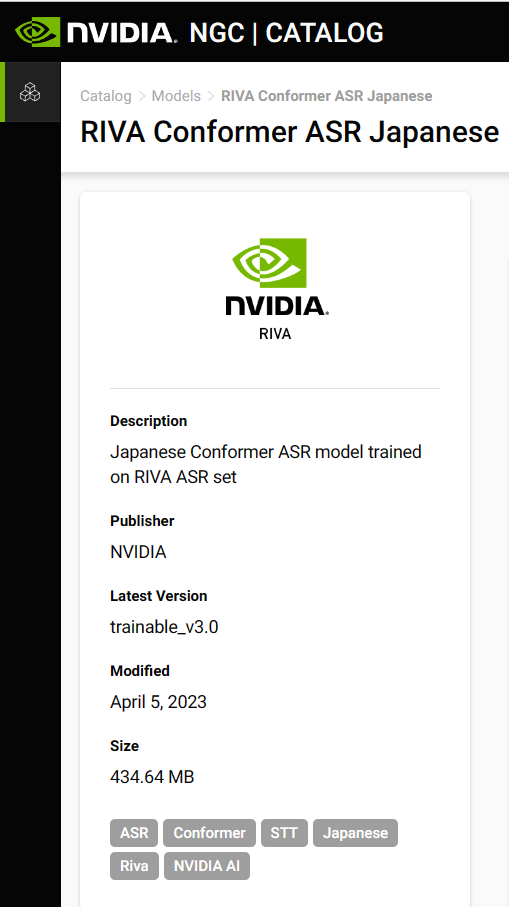
RIVA Conformer ASR Japanese:
https://resources.nvidia.com/en-us-riva-asr-briefcase/service-asr
GPU Notebook で動作確認してみた
環境:
・Lenovo Ideapad Gaming 3 シリーズ (AMD RYZEN7 + NVIDIA GeForece RTX 3050 Ti)
以上、ご覧いただきありがとうございました。